Qu'est-ce que la technologie Ceph¶
Ceph est une solution de stockage distribué (Software-Defined Storage ou SDS) open-source, conçue pour offrir un stockage à la fois unifié, hautement résilient et massivement évolutif (jusqu'à l'échelle de l'exaoctet).
Face aux architectures de stockage traditionnelles (NAS/SAN), Ceph apporte un changement de paradigme majeur reposant sur cinq piliers fondamentaux :
- Souveraineté matérielle (Pas de verrou constructeur) : Contrairement aux baies de stockage propriétaires, Ceph s'exécute sur du matériel serveur standard de l'industrie (Commodity Hardware). Vous êtes totalement libre de mixer des serveurs et des disques de générations ou de constructeurs différents (Dell, HPE, Supermicro, Lenovo...) au sein d'un même cluster. Cela garantit une maîtrise des coûts, une agilité d'approvisionnement et l'absence de vendor lock-in.
- Suppression des contrôleurs centralisés (Le "No SPOF") : Dans une architecture classique, les entrées/sorties (I/O) transitent par une paire de contrôleurs physiques qui finissent par saturer. Ceph élimine complètement le besoin d'un contrôleur centralisé pour les E/S. Grâce à l'algorithme intelligent CRUSH, les clients calculent eux-mêmes l'emplacement de leurs données et communiquent directement avec les disques (OSD). Il n'y a plus aucun goulot d'étranglement central.
- Le cycle de vie perpétuel (Évolution au fil des budgets) : Dans l'ESR, les budgets sont souvent liés à des plans de financement asynchrones (CPER, projets ANR, dotations d'universités). Ceph met fin au cycle douloureux du forklift upgrade (devoir tout jeter pour racheter une nouvelle baie car l'ancienne est en fin de support). Avec Ceph, on ajoute de nouveaux serveurs au fil des budgets et on retire les anciens serveurs obsolètes à chaud, sans une seule seconde de coupure pour les utilisateurs, les chercheurs ou les machines virtuelles.
- Convergence des usages (Unifié et Mutualisé) : Un seul et unique cluster Ceph peut simultanément répondre à tous les besoins de stockage d'un établissement ou d'un centre de calcul :
- du stockage Bloc (RBD) pour les clusters de virtualisation (Proxmox VE, OpenStack),
- du système de fichiers partagé (CephFS) pour les répertoires
/home, des projets ou les espaces de travail des clusters de calcul (HPC), - du stockage Objet (S3/Swift via RGW) pour la préservation des données de la recherche ou les plateformes de partage. Cela permet aux équipes d'administrateurs (ASR) de mutualiser leurs efforts sur un seul outil au lieu de maintenir trois technologies distinctes.
- Scalabilité linéaire des performances : Dans un système traditionnel, plus une baie se remplit, plus elle a tendance à ralentir sous la charge. Ceph fonctionne à l'inverse : chaque fois que vous ajoutez un serveur pour augmenter la capacité, vous injectez également de la bande passante réseau, des processeurs et de la mémoire RAM. Le cluster gagne ainsi en performance (débit et IOPS) à mesure qu'il grandit.
- Résilience native par le logiciel : Dans le monde Ceph, on considère que le matériel va faillir (un disque va mourir, un serveur va s'éteindre). C'est l'intelligence du logiciel qui gère la réplication, le code à effacement (Erasure Coding), la détection des pannes et la reconstruction automatique des données sans aucune interruption de service.
Comparaison avec les solutions de stockage traditionnelles:¶
| Caractéristique | Stockage traditionnel (SAN/NAS) | Ceph |
|---|---|---|
| Architecture | Centralisée | Distribuée |
| Scalabilité | Limitée | Quasi-illimitée |
| Flexibilité | Spécialisé (bloc, fichier) | Unifié (objet, bloc, fichier) |
| Coût | Coût élevé du matériel spécialisé | Coût réduit grâce au matériel standard |
| Gestion | Complexe, interface propriétaire | Simplicité grâce à une interface unifiée |
Les trois principaux types de stockage :¶
Ceph propose une approche unifiée du stockage, permettant de gérer différents types de données sur une même infrastructure.
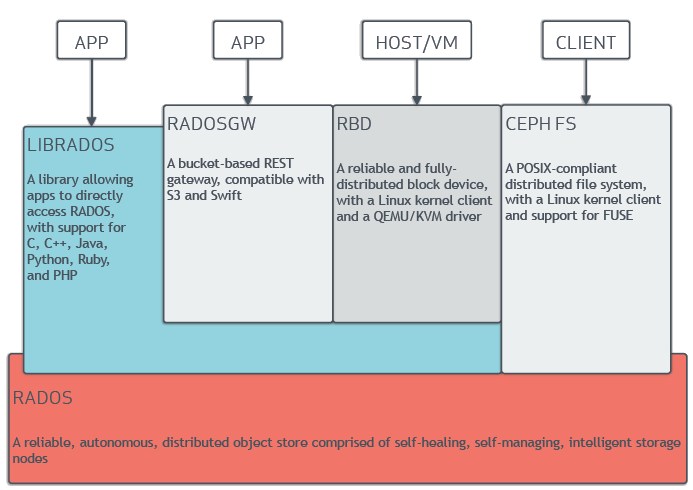
- Stockage objet (RADOSGW)
Concept: Les données sont stockées sous forme d'objets, identifiés par une clé unique. Chaque objet contient les données ainsi que des métadonnées associées (taille, date de modification, etc.).
Utilisation: Particulièrement adapté pour le stockage de fichiers de toutes tailles, les sauvegardes, les archives, les données non structurées (images, vidéos), et les applications cloud.
Avantages: Scalabilité quasi illimitée, haute disponibilité, accès rapide aux objets individuels. il n' a pas de fonction de partage, ni de verrous ou d’arborescence.
Exemple d'utilisation: Créer un bucket (conteneur) pour stocker des sauvegardes incrémentales de serveurs. - Stockage bloc (Rados Block Device RBD)
Concept: Les données sont stockées sous forme de blocs, comme un disque dur traditionnel.
Utilisation: Idéal pour les machines virtuelles (VM), les bases de données et les applications nécessitant un accès direct au bloc.
Avantages: Performances élevées pour les opérations d'E/S aléatoires, intégration facile avec les systèmes d'exploitation existants. Support des snapshots, du thin provisionning, de la compression. Dispose d'une solution de mirorring asynchrone, les fonctions de cache tiering (cache rapide en lecture ou écriture) et la passerelle iSCSI ne sont plus maitenu et seront remplacé par d'autre implémentation. il n'a pas de gestion d’accès concurrents, pas de déduplication.
Exemple d'utilisation: Attacher un volume Ceph RBD à une machine virtuelle pour stocker son système d'exploitation et ses données. - Système de fichiers distribué (CephFS)
Concept: Ceph offre un système de fichiers distribué POSIX compatible, permettant de monter des partages de fichiers sur différents nœuds du cluster.
Utilisation: Particulièrement adapté pour le partage de fichiers entre plusieurs utilisateurs, les applications nécessitant un système de fichiers traditionnel, et les environnements de type NAS (Network Attached Storage).
Avantages: Scalabilité, haute disponibilité, cohérence forte des données.
Problème : latence avec les petits fichiers et non recommandé pour les disques virtuels (double écriture, sécurité)
Exemple d'utilisation: Monter un partage de fichiers CephFS sur plusieurs serveurs pour stocker des fichiers de configuration, des documents ou des projets collaboratifs.
Choisir le bon type de stockage¶
Le choix du type de stockage dépendra de vos besoins spécifiques :
- Priorité à la scalabilité et à la flexibilité: Optez pour le stockage objet.
- Besoin de performances pour les E/S aléatoires et une intégration facile avec les systèmes existants: Choisissez le stockage bloc.
- Nécessité d'un système de fichiers POSIX compatible et d'un partage de fichiers centralisé: Utilisez CephFS.
Les cas d'utilisation typiques de Ceph :¶
voici les cas typiques d'utilisation de Ceph
1. Cloud Computing
Stockage d'objets pour les applications web: Ceph est idéal pour stocker des fichiers statiques (images, CSS, JS), des sauvegardes et des données utilisateur dans des environnements cloud.
Plateformes de virtualisation: En utilisant RBD (RADOS Block Device), Ceph peut fournir un stockage backend pour les machines virtuelles, offrant ainsi une solution de stockage élastique et performante.
Plateformes de conteneurs: Ceph peut être intégré avec des orchestrateurs de conteneurs comme Kubernetes pour fournir un stockage persistant aux conteneurs.
Stockage pour les services de sauvegarde et de restauration: Ceph est utilisé pour stocker les sauvegardes des données d'une infrastructure cloud, offrant une solution évolutive et fiable.
2. Big Data
Data lakes: Ceph peut servir de base à un data lake, permettant de stocker de grandes quantités de données brutes dans un format non structuré, en attendant d'être traitées.
Hadoop et Spark: Ceph est souvent utilisé comme système de stockage distribué pour les clusters Hadoop et Spark, offrant un stockage haute performance pour les données d'analyse.
Machine Learning: Ceph peut stocker les données d'entraînement et les modèles de machine learning, offrant une solution scalable et fiable pour les charges de travail de machine learning.
3. Haute disponibilité
Réplication des données: Ceph offre plusieurs niveaux de réplication en mode synchrone ou asynchrone pour assurer la haute disponibilité des données.
Tolérance aux pannes: Grâce à son architecture distribuée, Ceph peut tolérer des pannes de nœuds sans perte de données.
Récupération après sinistre: Ceph peut être utilisé pour mettre en place des solutions de réplication géographique afin de protéger les données contre les catastrophes naturelles.
Architecture et Fonctionnement¶

Ceph est constitué de plusieurs composants interconnectés, chacun jouant un rôle spécifique dans le stockage et la gestion des données. Ces briques de base sont constitués par :
- OSD (Object Storage Device):
Rôle: Ce sont les nœuds de stockage de base de Ceph. Ils sont responsables du stockage physique des données, fragmentées en objets.
Fonctionnement: Les OSD stockent les données sur des disques locaux ou sur des réseaux de stockage. Ils sont capables de gérer les opérations de lecture, d'écriture et de suppression sur ces objets.
- MON (Monitor):
Rôle: Les MON constituent le cerveau de Ceph. Ils forment un ensemble de processus qui gèrent la configuration du cluster, surveillent l'état des OSD, gèrent les identités et assurent la cohérence du système.
Fonctionnement: Les MON maintiennent un mappage de l'état du cluster, indiquant quels OSD sont en ligne, quels pools de stockage existent et où les données sont stockées. Ils utilisent un algorithme de consensus pour prendre des décisions de manière distribuée.
- MGR (Ceph Manager)
Introduits à partir de la version Luminous de Ceph, les MGR ont considérablement renforcé les capacités de gestion et de monitoring du cluster.
Rôle: Gestion des modules: Les MGR servent de plateforme pour exécuter des modules qui étendent les fonctionnalités de Ceph. Ces modules peuvent fournir des services additionnels tels que la gestion de quotas, la surveillance avancée, l'intégration avec des outils tiers, etc.
- Interface de gestion: Les MGR exposent une interface de gestion RESTful permettant d'interagir avec le cluster de manière programmatique. Intégration avec des systèmes de monitoring: Les MGR peuvent s'intégrer avec des outils de monitoring populaires comme Prometheus et Grafana pour fournir des métriques détaillées sur l'état du cluster.
Fonctionnement: Les MGR fonctionnent en parallèle des MON. Ils communiquent avec les MON et les OSD pour collecter des informations et exécuter les tâches de gestion. Les MGR peuvent être déployés sur des nœuds distincts ou co-localisés avec les MON.
- MDS (Metadata Server)
Rôle: Les MDS sont responsables de la gestion des métadonnées des fichiers dans CephFS (le système de fichiers distribué de Ceph). Ils maintiennent des informations sur les hiérarchies de fichiers, les permissions et les attributs sans devoir acceder directement aux objects stoqués dans les OSD. Ce rôle est nécessaire uniquement si vous utilisez un stockage CephFS.
Fonctionnement: Les MDS fournissent une interface POSIX pour les clients qui souhaitent accéder aux fichiers stockés dans Ceph.
Comment ces briques interagissent-elles ?¶
Les clients (applications, machines virtuelles, etc.) envoient des requêtes de lecture ou d'écriture aux MON.
Les MON déterminent l'OSD approprié pour répondre à la requête, en fonction de l'algorithme de placement des données (CRUSH).
Les clients communiquent directement avec l'OSD pour effectuer les opérations de stockage.
Les MDS gèrent les métadonnées des fichiers dans CephFS et fournissent une interface POSIX aux clients.
Qu'est-ce qu'un pool de stockage ?¶
Un pool de stockage dans Ceph permet d'organiser et de gérer efficacement les données au sein du cluster. Il peut être vu comme un conteneur logique qui regroupe un ensemble d'objets. C'est l'unité de base pour organiser les données et définir les politiques de stockage (réplication, taille maximale, etc.).
Pourquoi utiliser des pools ?¶
Isolation: Les pools permettent d'isoler les données de différentes applications ou projets.
Gestion des performances: On peut configurer différents pools avec des niveaux de réplication et de taille de bloc adaptés aux besoins de chaque application.
Sécurité: Les pools peuvent être utilisés pour mettre en œuvre des politiques de sécurité spécifiques (accès, chiffrement).
Comment fonctionnent les pools ?¶
Création: Un administrateur crée un pool en spécifiant sa taille maximale, son niveau de réplication et d'autres paramètres.
Placement des données: Lorsque des données sont écrites dans Ceph, l'algorithme CRUSH (Controlled Replication Under Scalable Hashing) détermine sur quels OSD les données doivent être répliquées.
Réplication: Les données sont répliquées sur plusieurs OSD pour assurer la redondance et la haute disponibilité. Le niveau de réplication peut être configuré par pool.
Équilibrage de charge: Ceph s'assure que les données sont réparties de manière équilibrée sur tous les OSD du cluster.
Les principaux paramètres d'un pool:¶
Taille maximale: Limite la quantité de données pouvant être stockée dans un pool.
Définition d'une politiques de stockage en fonction :
- Du type de matériel (disques SATA,SSD,MVME,…)
- De la sécurité des données (Replicated vs Erasure Coding)
Niveau de réplication: Nombre de copies d'un objet stocké dans le cluster.
Taille de bloc: Taille des blocs de données utilisés pour le stockage.
Type de données: Objet, bloc ou fichier.
Authentification : règles d’accès en lecture ou en écriture pour les clients (service)
Supervision des statistiques de chaque pool
Gestion des Placement Groups (PG) et PG Autoscaler¶
Dans l'architecture Ceph, la distribution des données, la tolérance aux pannes et les performances dépendent d'un concept clé : les Placement Groups (PG). Comprendre leur fonctionnement et savoir les configurer est indispensable pour opérer un cluster stable, en particulier dans les environnements de l'Enseignement Supérieur et de la Recherche (ESR) où les volumétries et les profils d'I/O (calcul haute performance, stockage objet, virtualisation) sont très variés.
1. Qu’est-ce qu’un Placement Group (PG) ?¶
Si Ceph devait suivre et cartographier l'emplacement de chaque fichier ou objet individuel sur chaque disque du cluster, la table d'indexation (metadata) deviendrait tellement gigantesque qu'elle saturerait la mémoire RAM de tous les serveurs du pool, créant un goulot d'étranglement systémique.
Pour résoudre ce problème d'échelle, Ceph introduit une couche logique intermédiaire : les Placement Groups (PG).
- Le principe : Un pool (espace de stockage logique dédié à un usage) est découpé en un nombre fini de PG. Lorsqu'un client écrit un objet, Ceph applique une fonction de hachage sur le nom de cet objet pour lui attribuer de manière déterministe un PG spécifique.
- Le rôle de CRUSH : C'est ensuite l'algorithme CRUSH (Controlled Replication Under Scalable Hashing) qui prend le relais. Sans base de données centrale, CRUSH détermine dynamiquement sur quels OSD (disques physiques) ce PG — et donc tous les objets qu'il contient — doit être stocké et répliqué.
💡 La métaphore de la Poste : Imaginez que vos objets stockés soient des lettres. Au lieu de donner au facteur le chemin exact pour chaque lettre individuelle à travers le pays, Ceph trie les lettres par Code Postal (le PG). Le facteur (l'algorithme CRUSH) sait instantanément dans quel centre de tri et dans quelle boîte (l'OSD) distribuer le courrier uniquement en lisant ce code postal.
2. Pourquoi le nombre de PG est-il critique ?¶
Historiquement, le choix du nombre de PG par pool (pg_num) était l'une des tâches les plus complexes de l'administrateur Ceph. Un mauvais dimensionnement a des conséquences directes sur la production :
- Sous-dimensionnement (Pas assez de PG) : * Déséquilibre des données (Data Skew) : La granularité est trop grossière. Certains OSD se retrouveront pleins à craquer tandis que d'autres resteront sous-utilisés.
- Reconstructions lentes : En cas de panne d'un disque, le processus de reconstruction (recovery) implique peu de PG, limitant le nombre d'OSD partenaires capables de participer simultanément à l'effort de réplication.
- Sur-dimensionnement (Trop de PG) :
- Surcharge de ressources : Chaque PG consomme du CPU et de la mémoire RAM sur les démons OSD. Un excès de PG peut saturer la mémoire des serveurs de stockage.
- Instabilité réseau : En cas de coupure réseau transitoire ou de redémarrage d'un nœud, les mécanismes de synchronisation (peering) entre un nombre trop élevé de PG peuvent saturer les liens réseau et figer le cluster.
3. L'automatisation : Le PG Autoscaler¶
Pour simplifier l'exploitation, Ceph intègre nativement le module PG Autoscaler (géré par le démon ceph-mgr). L'Autoscaler analyse en continu l'espace disque consommé, le nombre d'objets et la capacité globale afin d'ajuster automatiquement, en tâche de fond et à chaud, le nombre de PG d'un pool.
Configuration des modes de l'Autoscaler¶
Le comportement de l'Autoscaler peut être défini individuellement par pool à l'aide de la commande suivante :
Le paramètre <mode> accepte trois valeurs :
on(Par défaut sur les versions récentes) : Ceph ajuste automatiquement le nombre de PG. Les augmentations ou diminutions se font par puissances de 2 (ex. de 32 à 64, puis 128) afin de minimiser l'impact des mouvements de données lors du redéploiement.warn: Ceph n'applique aucune modification automatique. En revanche, si l'Autoscaler détecte une anomalie ou un besoin d'optimisation, il lève une alerte dans le statut du cluster (HEALTH_WARN : 1 pools have many more pgs than ideal).off: Désactive complètement l'automatisme pour le pool concerné. Ce mode est réservé aux architectures figées ou très spécifiques pilotées manuellement par des experts.
4. Bonnes pratiques et Recommandations pour l'ESR¶
Bien que le PG Autoscaler réduise considérablement la charge mentale de l'exploitant, il ne peut pas deviner l'évolution future de vos infrastructures. Sans indications préalables, l'Autoscaler initialise souvent les nouveaux pools avec un très petit nombre de PG (32), ce qui provoque de lourds mouvements de données (backfills) lorsque le pool se remplit massivement.
Voici les règles d'or recommandées par le Groupe de Travail pour optimiser vos déploiements :
A. Indiquer les pools massifs via le Bulk Flag¶
Si vous créez un pool destiné à recevoir immédiatement de grosses volumétries de données (par exemple un pool de sauvegarde externalisée, un dépôt d'images de VM, ou le stockage de données brutes scientifiques), activez l'indicateur bulk dès sa création :
Effet : Ceph comprend que ce pool a vocation à occuper une place importante. L'Autoscaler va directement lui allouer un nombre élevé de PG de départ, évitant des vagues successives et chronophages de rééquilibrage en production.
B. Anticiper la répartition de l'espace (target_size_ratio)¶
Si vous connaissez à l'avance la répartition théorique des différents usages sur votre cluster (par exemple : un cluster mixte hébergeant des disques de VM et du stockage objet S3), vous devez configurer le ratio cible de chaque pool :
# Exemple : On prévoit que RBD (VMs) occupera 60% du cluster et RGW (S3) occupera 40%
ceph osd pool set pool_proxmox_rbd target_size_ratio 0.6
ceph osd pool set pool_rgw_data target_size_ratio 0.4
Effet : Dès la création, l'Autoscaler calcule le nombre optimal de PG proportionnellement à la taille finale estimée, garantissant des performances lisses dès le premier jour.
5. Supervision et Commandes Utiles¶
Pour auditer l'état de vos Placement Groups et analyser les décisions prises par le gestionnaire automatique, utilisez la commande de référence :
Cette commande retourne un tableau structuré contenant les métriques suivantes :
| Colonne | Description |
|---|---|
| POOL | Le nom du pool de stockage. |
| SIZE | Le volume de données utiles actuellement stockées. |
| TARGET SIZE / RATIO | La taille ou le ratio cible configuré manuellement par l'administrateur. |
| PG_NUM | Le nombre actuel de Placement Groups affectés au pool. |
| NEW PG_NUM | La valeur idéale calculée par l'Autoscaler. Si le mode est sur on, PG_NUM migrera vers cette valeur. |
| AUTOSCALE | Le mode actif (on, warn, off). |
Vérifier la santé globale des PG¶
Pour s'assurer qu'aucun PG n'est bloqué dans un état anormal (degraded, undersized, peering), la commande de routine reste :
Qu'est-ce que CRUSH ?¶
CRUSH (Controlled Replication Under Scalable Hashing) est un algorithme de hachage qui permet de mapper les données sur les OSD de manière déterministe et équilibrée. Il prend en compte la topologie physique du cluster (racks, baies, etc.) pour assurer une bonne répartition des données et une haute disponibilité.
Comment fonctionne CRUSH ?¶
Carte CRUSH: Cette carte représente la topologie physique du cluster. Elle est constituée d'une hiérarchie de nœuds, allant des plus généraux (par exemple, des data centers) aux plus spécifiques (les OSD).
Calcul du PG: Comme vu précédemment, chaque objet est assigné à un placement group (PG). Le PG est calculé à partir de l'identifiant de l'objet et d'autres paramètres.
Recherche des OSD: En utilisant la carte CRUSH et l'algorithme de hachage, Ceph détermine les OSD qui doivent stocker les répliques de l'objet associé au PG.
Les avantages de CRUSH¶
Répartition équilibrée: CRUSH garantit une répartition équilibrée des données sur les OSD, ce qui améliore les performances et la disponibilité.
Scalabilité: L'algorithme peut s'adapter à des clusters de taille variable.
Flexibilité: La carte CRUSH peut être modifiée pour refléter les changements dans la topologie du cluster.
Déterminisme: Le placement des données est déterministe, ce qui facilite la récupération des données en cas de panne.
Les composants clés de la carte CRUSH¶
Nœuds: Représentent les différents niveaux de la hiérarchie (data centers, racks, OSD, etc.).
Arêtes: Connectent les nœuds entre eux.
Poids: Associés aux nœuds, les poids déterminent la probabilité qu'un objet soit stocké sur un OSD donné.
Règles: Définissent la manière dont les objets sont mappés sur les OSD.
Exemple simplifié¶
Imaginez un cluster avec deux racks, chaque rack contenant plusieurs OSD. La carte CRUSH pourrait être structurée de la manière suivante :
Niveau 1: Data center
Niveau 2: Rack 1, Rack 2
Niveau 3: OSD 1, OSD 2, ...
Lorsqu'un objet est écrit dans Ceph, CRUSH utilise la carte pour déterminer sur quels OSD les répliques de l'objet doivent être placées. Par exemple, il pourrait décider de stocker une réplique sur un OSD du Rack 1 et une autre sur un OSD du Rack 2, afin de répartir les données de manière équilibrée.
En résumé, CRUSH est un algorithme puissant et flexible qui joue un rôle central dans la gestion du stockage dans Ceph. Il garantit une répartition équilibrée des données, une haute disponibilité et une scalabilité.
Qu'est-ce qu'un domaine de défaillance ?¶
Un domaine de défaillance est une unité logique qui regroupe des éléments physiques (serveurs, racks, baies, etc.) susceptibles de tomber en panne simultanément. L'idée est de s'assurer que les réplicas d'un objet ne soient pas tous situés dans le même domaine de défaillance, afin de minimiser le risque de perte de données en cas de panne.
Pourquoi est-ce important ?¶
Haute disponibilité: En répartissant les données sur différents domaines de défaillance, on réduit le risque de perte de données en cas de panne d'un élément physique (par exemple, un rack). Durabilité: Les domaines de défaillance permettent de protéger les données contre des événements catastrophiques (incendie, inondation, etc.).
Exemple¶
Imaginez un cluster Ceph réparti sur trois serveurs de données. Par defaut le domaine de defaillance est dinit par serveur. Si un objet est répliqué trois fois, CRUSH s'assurera que les trois répliques sont stockées sur des OSD situés dans ou moins 3 serveurs différents. Ainsi, même si un serveur de données entier tombe en panne, les données seront toujours accessibles.
Les différents niveaux de domaines de défaillance:¶
Server: Le domaine de défaillance le plus courant. Il regroupe tous les OSD d'un même serveur.
Baie: Un domaine de défaillance peut également être défini au niveau d'une baie de stockage.
Centre de données: Pour les déploiements à grande échelle, on peut définir des domaines de défaillance au niveau des centres de données.
En résumé, les domaines de défaillance sont un mécanisme essentiel pour garantir la haute disponibilité et la durabilité des données dans un cluster Ceph. En configurant correctement les domaines de défaillance dans la carte CRUSH, on peut protéger les données contre une large gamme de pannes.
La protection des données¶
Le choix entre la réplication et l'erasure code dépend de vos besoins spécifiques en termes de disponibilité, de performance et de capacité de stockage. Il est souvent recommandé de combiner les deux mécanismes pour obtenir un équilibre optimal entre ces différents critères. Par exemple, vous pouvez utiliser la réplication pour les données les plus critiques et l'erasure code pour les données moins sensibles.
La réplication¶
La réplication est le mécanisme de protection des données le plus simple à comprendre. Elle consiste à créer plusieurs copies identiques d'un objet et à les stocker sur différents OSD. Si un OSD tombe en panne, les autres répliques peuvent être utilisées pour reconstruire les données perdues.
- Avantages:
Simple à mettre en œuvre: La réplication est facile à comprendre et à configurer.
Bonne performance pour les petites écritures: La réplication est généralement plus performante que l'erasure code pour les petites écritures.
- Inconvénients:
Coût de stockage élevé: La réplication nécessite de stocker plusieurs copies d'un même objet, ce qui peut augmenter considérablement les coûts de stockage.
Limite de disponibilité: Si vous avez besoin d'une très haute disponibilité, il peut être nécessaire d'utiliser un nombre élevé de répliques, ce qui peut encore augmenter les coûts.
Erasure Code¶
L'erasure code est un mécanisme plus sophistiqué qui permet de reconstruire les données perdues à partir d'un nombre réduit de fragments. Au lieu de créer des copies identiques d'un objet, l'erasure code divise l'objet en plusieurs morceaux (données) et crée des morceaux de parité supplémentaires. Ces morceaux sont ensuite répartis sur différents OSD.
- Avantages:
Économie de stockage: L'erasure code nécessite moins d'espace de stockage que la réplication pour un niveau de protection équivalent.
Haute disponibilité: L'erasure code permet de reconstruire les données perdues même si plusieurs morceaux sont perdus.
- Inconvénients:
Complexité: L'erasure code est plus complexe à mettre en œuvre que la réplication.
Performance: Les opérations de lecture et d'écriture peuvent être légèrement plus lentes avec l'erasure code, en particulier pour les petites écritures.
Quand choisir quel mécanisme ?¶
- Réplication:
Si vous avez besoin d'une solution simple et performante pour les petites écritures.
Si vous êtes prêt à accepter des coûts de stockage plus élevés. - Erasure code:
Si vous avez besoin d'optimiser l'utilisation de l'espace de stockage.
Si vous avez besoin d'une très haute disponibilité.
Si vous êtes prêt à accepter des performances légèrement inférieures pour les petites écritures.
Qu'est-ce que Cephx ?¶
Cephx est un protocole d'authentification cryptographique conçu spécifiquement pour Ceph. Il utilise des clés secrètes partagées pour vérifier l'identité des clients et des différents composants du cluster (MON, OSD, etc.) garantissant ainsi l'intégrité et la confidentialité des données.
Comment fonctionne Cephx ?¶
Génération des clés: Au cours du déploiement de Ceph, des clés secrètes uniques sont générées pour chaque entité (client, MON, OSD). Ces clés sont stockées de manière sécurisée.
Authentification initiale: Lorsqu'un client souhaite se connecter au cluster, il présente sa clé secrète au MON. Le MON vérifie la validité de cette clé par rapport à sa base de données de clés.
Émission d'un ticket: Si l'authentification est réussie, le MON émet un ticket chiffré avec la clé secrète du client. Ce ticket contient une clé de session temporaire qui sera utilisée pour les communications suivantes.
Utilisation du ticket: Le client utilise le ticket pour s'authentifier auprès des OSD. Les OSD vérifient la validité du ticket en utilisant la clé secrète partagée avec le MON.
Renouvellement des tickets: Les tickets ont une durée de vie limitée pour renforcer la sécurité. Ils doivent être renouvelés régulièrement.
Les avantages de Cephx¶
Sécurité renforcée: Cephx protège les données contre les accès non autorisés en vérifiant l'identité de chaque entité qui se connecte au cluster.
Flexibilité: Cephx permet de définir des niveaux d'accès différents pour les différents utilisateurs et entités.
Intégration transparente: Cephx est intégré de manière transparente dans Ceph, ce qui facilite sa configuration et son utilisation.
Évolutivité: Cephx peut être utilisé dans des environnements de grande taille avec un grand nombre de clients et d'OSD.
Les principales caractéristiques de Cephx¶
Authentification mutuelle: Le client et le serveur se vérifient mutuellement l'identité.
Clés secrètes partagées: Les clés secrètes sont utilisées pour chiffrer les communications et vérifier l'authenticité des messages.
Tickets: Les tickets sont utilisés pour authentifier les clients auprès des OSD.
Durée de vie limitée des tickets: Les tickets expirent après un certain temps pour renforcer la sécurité.